IA Local, Privacidad y Automatización: Traduciendo mi Portafolio con Ollama
Un análisis profundo sobre cómo implementar un flujo de traducción automatizado utilizando LLMs locales (Ollama + Llama 3) en un entorno Hackintosh. Arquitectura, ventajas, desventajas y código.

En la era de la inteligencia artificial generativa, depender de APIs en la nube (como OpenAI o Anthropic) se ha convertido en el estándar por defecto para la mayoría de los desarrolladores. Es “fácil”: pagas, envías un JSON, recibes una respuesta. Sin embargo, para proyectos personales, la dependencia de servicios de terceros introduce fricción: costos recurrentes, latencia de red, gestión de claves de API y, sobre todo, preocupaciones crecientes sobre la privacidad de los datos.
En este artículo extenso, desglosaré paso a paso cómo he implementado un sistema de traducción automática 100% local para este portafolio, utilizando Ollama, Node.js y Git Hooks. Este sistema me permite escribir contenido exclusivamente en español y delegar la internacionalización a mi propio hardware, sin salir de mi terminal y sin pagar un centavo extra.
El Problema con la Nube
Antes de entrar en el código, analicemos por qué alguien querría complicarse la vida montando infraestructura local cuando GPT-4 existe.
1. Costo Marginal vs. Costo Fijo
Las APIs de LLM cobran por token. Aunque barato, el costo psicológico de “pagar por probar” frena la innovación. Si quiero re-traducir todo mi blog (100 posts) porque cambié el prompt para que suene más “profesional”, eso tiene un costo en dólares. Con una LLM local, el costo marginal es cero (o mejor dicho, el costo de la electricidad). Puedo iterar el prompt 50 veces hasta que quede perfecto.
2. Latencia y Flujo de Trabajo
Depender de la nube implica red. Si estoy programando en un avión, en un café con mal WiFi, o simplemente se cae el servicio, mi flujo de CI/CD se rompe. Un modelo local vive en mi NVMe. Siempre está ahí.
3. Privacidad por Diseño
Este es un punto crucial. Mis borradores, mis notas personales desordenadas, mis comentarios internos… nada de eso debería salir de mi máquina hasta que yo decida publicarlo. Al usar una API externa, estás enviando tu proceso creativo crudo a servidores ajenos. Al usar IA local, el proceso de refinamiento es privado.
La Solución: Ollama + Llama 3
Ollama ha democratizado la inferencia local. Antes, correr un modelo cuantizado requería compilar llama.cpp a mano, entender parámetros oscuros de CUDA/Metal y luchar con dependencias de Python. Ollama empaqueta todo esto en un binario simple escrito en Go.
Para este proyecto, utilizo Llama 3 (8B).
- ¿Por qué 8B?: Es el punto dulce. Los modelos de 70B son demasiado pesados para una GPU de consumidor promedio (requieren ~48GB VRAM para correr cómodamente). El modelo de 8B corre perfectamente en 8GB-16GB de RAM/VRAM con una velocidad de inferencia superior a la velocidad de lectura humana.
- Calidad de Traducción: Para traducción inglés-español, Llama 3 ha demostrado ser sorprendentemente capaz, entendiendo matices técnicos mejor que modelos anteriores como Mistral 7B.
Arquitectura del Sistema
El flujo de trabajo es transparente e invisible. No hay interfaz gráfica, no hay botones de “Traducir”. La traducción es un efecto secundario de mi flujo de trabajo en Git.
Componente 1: El Motor (auto-translate.js)
Este script de Node.js es el orquestador. No se limita a enviar texto ciegamente; entiende la semántica de mis archivos Markdown.
Desafío: El Contexto y el Frontmatter
Los generadores de sitios estáticos (como Astro, que uso aquí) dependen del “Frontmatter” (metadatos YAML al inicio del archivo). Un error común al traducir con IA es que el modelo, en su afán de ayudar, traduce todo, rompiendo el código.
Si tengo:
tags: ["technical", "personal"]Y la IA me devuelve:
etiquetas: ["técnico", "personal"]Mi sitio se rompe. El script debe ser quirúrgico.
La Implementación
Utilizo la librería gray-matter para separar contenido y metadatos. He aquí la lógica simplificada:
/* scripts/auto-translate.js (Simplificado) */
async function processPost(filePath) {
const { data, content } = matter(read(filePath));
// 1. Traducir metadatos específicos
const newTitle = await translate(data.title);
const newDesc = await translate(data.description);
// 2. Traducir el cuerpo
// Aquí está el truco: NO enviamos todo el cuerpo de una vez.
// Los LLMs tienen ventana de contexto limitada y pueden "alucinar" en textos largos.
// Dividimos por encabezados (##).
const sections = content.split(/(\n## )/);
const translatedSections = await Promise.all(sections.map(translate));
// 3. Reconstruir
return matter.stringify(translatedSections.join(''), {
...data,
title: newTitle,
description: newDesc
});
}Componente 2: Diccionario de Exclusiones (translation-overrides.json)
Ninguna IA es perfecta. En el mundo del desarrollo, usamos términos en inglés que no deben traducirse. “Dotfiles” no es “Archivos de punto”. “Framework” no siempre es “Marco de trabajo”. “Hackintosh” definitivamente no debe traducirse.
Para resolver esto sin complicar el prompt, implementé un sistema de “hard-override”. Antes de llamar a la IA, el script consulta un JSON local.
{
"Dotfiles": "Dotfiles",
"Silakka54: Ergonomía Programable": "Silakka54: Programmable Ergonomics",
"Loutaif Connect": "Loutaif Connect"
}Esto me da control total y determinista sobre los nombres propios de mis proyectos. Es una capa de seguridad semántica.
Componente 3: Automatización Escalable con Husky
Para garantizar que nadie (ni yo ni otro colaborador) pueda romper la sincronización entre el español y el inglés, reemplazamos los scripts manuales con Husky.
Husky gestiona los Git Hooks de manera profesional y versionada.
- Instalación:
npm install husky - Hook:
.husky/pre-commit
El contenido del hook es la última línea de defensa:
#!/bin/sh
. "$(dirname "$0")/_/husky.sh"
# 1. Ejecutar traducción (Rápido gracias al Caché MD5)
npm run translate
# 2. Agregar los archivos generados al commit en curso
git add src/content/posts/en¿Por qué es mejor?
A diferencia de un hook manual en .git/hooks/ (que no se comparte al clonar el repo), la configuración de Husky vive en package.json y el repositorio. Si clonas este proyecto mañana en otra Mac, npm install configurará automáticamente la protección de traducción. Cero olvidos, escalabilidad total.
Esto cambia fundamentalmente la experiencia de escritura.
- Escribo
mi-post.md. - Hago
git commit -m "New post". - Veo en la consola “Procesando…”.
- Unos segundos después, el commit se completa y ya incluye la versión en inglés.
Análisis de Rendimiento y Hardware: La Realidad de la RX 580 en Hackintosh
Mi estación de trabajo es un Hackintosh con un procesador Intel Core i7 14700K y una AMD Radeon RX 580 (8GB). Al implementar este sistema, me encontré con un caso de estudio técnico fascinante sobre la compatibilidad de Metal.
La Dicotomía de Metal: Gráficos vs. Cómputo
MacOS maneja la RX 580 de manera excelente para la interfaz visual, juegos y renderizado de video, utilizando lo que podríamos llamar Metal Graphics. Sin embargo, la inferencia de IA requiere Metal Compute.
Ollama (basado en llama.cpp) utiliza kernels de Metal agresivamente optimizados para Apple Silicon (M1/M2/M3). La arquitectura Polaris de la RX 580 carece de ciertas instrucciones modernas que estos kernels esperan. Al detectar esto, Ollama realiza un “fallback” inteligente:
- Intenta inicializar Metal.
- Detecta incompatibilidad de cómputo en la GPU.
- Deriva la carga a la CPU para asegurar la estabilidad.
Rendimiento Real (CPU Inference)
En lugar de usar la VRAM, el modelo corre en la RAM del sistema y es procesado por los núcleos del i7.
| Métrica | Valor (i7 14700K) |
|---|---|
| Modelo | Llama 3 (8B) |
| Backend | CPU (AVX2) |
| Uso de GPU | 0% (Solo Video) |
| Velocidad | ~11 tokens/segundo |
Aunque una GPU moderna o Apple Silicon alcanzaría 40+ t/s, 11 t/s es perfectamente funcional para un proceso en segundo plano. Un artículo de 1000 palabras toma unos 2-3 minutos en traducirse. Durante este tiempo, los ventiladores del CPU subirán de revoluciones, pero el sistema permanece estable y la traducción se completa sin errores.
Desafíos Encontrados y Soluciones
1. Alucinaciones en Textos Largos
Inicialmente, intenté enviar el post entero a la IA. Resultado: En posts largos, a partir del tercer párrafo, la IA empezaba a resumir en lugar de traducir, o cambiaba el tono, o insertaba comentarios como “Here represents the translation…“.
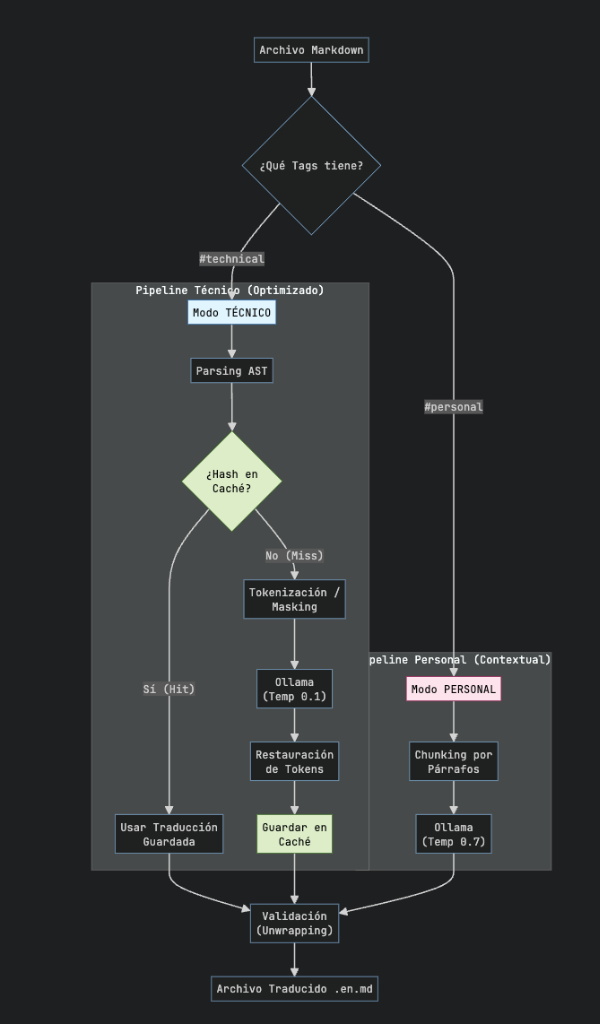
2. Evolución 3.0: Tokenización, Smart Router y “Personalidades”
Originalmente, intenté usar Regex, luego pasé a un AST quirúrgico. Ambos tenían fallos: el Regex rompía código, y el AST a veces duplicaba encabezados o rompía la sintaxis de imágenes () si el LLM decidía ser “creativo”.
La solución definitiva (versión actual) implementa tres técnicas avanzadas:
A. Tokenización (Masking)
La regla de oro: “Si no quieres que la IA lo rompa, no se lo muestres”.
Antes de enviar el texto a Llama 3, el script escanea el Markdown buscando elementos volátiles (imágenes ![], bloques de código inline).
- Secuestro: Reemplaza
por un token opaco:__IMG_0__. - Traducción: El LLM recibe: “Translate this: IMG_0 is amazing.”
- Restauración: Al recibir la respuesta, el script busca
__IMG_0__y vuelve a insertar la imagen original. Resultado: Cero imágenes rotas. Garantizado.
B. Smart Router (“Doble Personalidad”)
No todo el contenido es igual. Una nota técnica sobre Kernels necesita precisión; un poema o ensayo necesita “alma”.
El script ahora lee las etiquetas (tags) del post y elige el algoritmo:
| Modo | Trigger (Tag) | Temperatura | Estrategia | Objetivo |
|---|---|---|---|---|
| Técnico | technical | 0.1 (Frío) | AST + Masking | Precisión absoluta. Traduce nodo por nodo. Lento pero seguro. |
| Personal | personal | 0.7 (Creativo) | Chunking | Fluidez. Traduce párrafos enteros para mantener el contexto literario. Rápido. |
C. Lógica de Des-anidado (Unwrapping)
Un bug persistente era que el LLM devolvía encabezados dobles (## ## Título).
Implementé una validación post-traducción que compara la estructura del nodo original con el traducido. Si ambos son encabezados, extraigo el texto interno para evitar la duplicación de hashtags.
3. El Costo de la Precisión (CPU Time)
Al correr en modo Técnico (AST nodo por nodo) en la CPU, el tiempo de traducción es considerable (~20-25 minutos para un post largo). Es el precio a pagar por la privacidad y la precisión. Mientras la GPU (RX 580) maneja el escritorio fluido, el i7 procesa silenciosamente en segundo plano. La automatización no necesita ser instantánea, solo necesita ser desatendida.
4. Optimización Final: Solucionando la “Amnesia” con Hashing (MD5)
Tras varias iteraciones, identificamos una ineficiencia crítica en el pipeline Técnico. El script operaba de manera “stateless” (sin memoria): si tenía un artículo de palabras y agregaba un párrafo nuevo de palabras, el sistema volvía a traducir la totalidad ().
Esto desperdiciaba ciclos de CPU re-traduciendo contenido estático. La solución fue implementar una capa de caché persistente:
- Hashing: Antes de procesar un nodo, calculamos su hash MD5.
- Lookup: Consultamos una base de datos local (
translation-cache.json). - Decisión: Si el hash existe (Hit), recuperamos la traducción en 0ms. Solo si es contenido nuevo (Miss), invocamos a la IA.
Nota Técnica: Esta optimización es exclusiva del modo Técnico, donde los párrafos son independientes y el contexto previo no altera el significado técnico. En el modo Personal, deshabilitamos el caché intencionalmente: en narrativa, el contexto () afecta semánticamente a lo nuevo (), por lo que es necesario regenerar el flujo completo para mantener la coherencia literaria.
Conclusión
Integrar IA local en el flujo de desarrollo web es más que una curiosidad técnica; es una declaración de principios sobre la propiedad de nuestras herramientas.
Hemos construido un sistema que es:
- Privado: Nada sale de
localhost. - Gratuito: Sin facturas de API.
- Robusto: Funciona offline y con control total sobre el diccionario.
- Transparente: Integrado en
git commit.
Este enfoque es aplicable a documentación técnica, wikis corporativas internas, o cualquier sistema de gestión de conocimiento donde la privacidad y el costo sean factores.
Si tienes una GPU decente (incluso integrada en los nuevos Macs), te invito a probarlo. La sensación de ver a tu propia máquina “pensar” y trabajar para ti es, sencillamente, el futuro de la informática personal.